0x01 简介
- 出处(期刊):
- IEEE TRANSACTIONS ON RELIABILITY( Volume: 67, Issue: 3, Sept. 2018)
- JCR Q1
- SCI Q1
- 作者及单位:
- HongLiang Liang: Member, IEEE
- Xiaoxiao Pei: Member, IEEE
- Xiaodong Jia: Member, IEEE
- Wuwei Shen: Member, IEEE
- Jian Zhang: Senior Member, IEEE
- 关键词:
- Index Terms-Fuzzing
- reliability
- security
- Software testing
- Survey
0x02 摘要
模糊测试(fuzzing, short for fuzz testing)作为一种流行的软件测试技术,它能通过生成的大量输入发现程序的很多bug或漏洞。由于它的有效性,故其被视作一种有价值的bug发现方法。本文重点概述了fuzzing的一般过程及其类型,详细讨论了目前存在的关键问题及克服或减轻这些问题的先进技术。进一步将几个广泛使用的fuzzing工具进行分析、分类。本文的主要目标是让读者更好的了解fuzzing,及在软件测试和安全领域对fuzzing改进的潜在解决方案。最后还预测了fuzzing未来的一些方向。
0x03 结论
Fuzzing是一种能自动、高效地发现程序bug和漏洞的软件测试技术。根据目标程序中获取的信息量,它可以分为黑盒、白盒和灰盒三类。在fuzzing过程中,发现bug的基本方法是生成大量的测试用例,这些测试用例有望在目标程序中触发导致bug的代码片段。但是fuzzing生成测试用例没有固定的模式,主要取决于开发人员的创造性。作者对1990年1月至2017年6月期间发表的171篇论文进行了一项调查。结果表明,fuzzing是一个蓬勃发展的话题。目前,与fuzzing融合的技术包括遗传算法、污点分析、符号执行、覆盖率引导方法等。现有的fuzzing工具已广泛应用于编译器、网络协议、应用程序、内核等等多种工业产品中。从二进制文件到源代码,fuzzing发现了数万个软件bug,且其中许多是可利用的。最后,我们讨论了一些fuzzing的开放性问题。以鼓励进一步的研究和实践来解决这些问题,以便在软件系统的持续集成中广泛的适应fuzzing。
0x04 引言
Fuzzing 是“一种自动测试技术,它覆盖了大量边界情况,将有效数据(来自文件、网络协议、应用程序接口(API)调用和其他目标)用作应用程序输入,以更好地确保不存在可利用的漏洞”[1]。Fuzzing最早由Milleret al[2]于1988年提出,自那时起,它已发展成为一种有效、快速、实用的方法,用于发现软件中的错误[3]-[5]。fuzzing 的关键思想是生成并向目标程序提供大量可能触发软件错误的测试用例。fuzzing最具创造性的部分是生成合适的测试用例的方法,当前流行的方法包括覆盖率引导策略、遗传算法、符号执行、污点分析等。基于这些方法,现代模糊化技术非常智能,能够发现隐藏的bug。因此,作为一种独特的测试方法,测试成功可以用有意义的软件质量术语来量化,fuzzing具有重要的理论和实验作用。它作为比较其他方法的标准[6]。此外,fuzzing已逐渐发展成为一种综合技术,它将目标程序的静态和动态信息进行同步组合,以便生成更好的测试用例并检测到更多错误。
Fuzzing通过不断向目标程序发送格式错误或半有效的测试用例来模拟攻击。由于这些不规则的输入,Fuzzer(也称为fuzzing工具)经常可以发现以前未知的漏洞[8]–[11]。这是 fuzzing 在软件测试中扮演重要角色的关键原因之一。然而,在测试用例生成过程中的盲目性可能导致低代码覆盖率,这是 fuzzing 一直试图克服的主要缺点。如上所述,fuzzing 已经使用了几种方法来缓解这个问题并取得了令人印象深刻的进展。如今,模糊技术已被广泛应用于测试各种软件,包括编译器、应用程序、网络协议、内核等,以及多个应用领域,如syn-tax错误恢复评估[12]和故障定位[13]。
A. 动机
有两个原因促使作者写这篇综述。
- 因为 Fuzzing 能高效地发现bug,故其在软件安全性和可靠性领域得到越来越多的关注。许多诸如谷歌、微软等IT公司正在研究 fuzzing 技术并进一步开发模糊测试工具(如SAGE[14]、Syzkaller[15]、SunDew[16]等)来发现目标程序中的漏洞。
- 过去几年中,没有对 fuzzing 进行系统的评论。尽管一些论文对 fuzzing 进行了概述,但它们通常是对选定文章[1],[17]的回顾,或是对特定测试主题的调查[18],[19]。因此,作者认为有必要对这一领域的最新研究方法和最新研究成果进行全面地综述。因此,通过本文,作者希望不仅初学者能对 fuzzing 有一个大致的了解,并且专业人士也能对 fuzzing 有一个全面的回顾。
B. 大纲
本文的其余部分如下:第五节介绍了作者在调查中使用的审查方法,及对一些选定论文对简要总结和分析。第六节描述了 fuzzing 的一般过程。 第七节介绍了 fuzzing 的分类。 第八节描述了 fuzzing 的最新技术。第九节介绍了几种流行的 fuzzing 工具,它们按应用领域和问题领域进行了分类。 根据作者的调查结果, 第十节确定了一些研究挑战作为未来研究的途径。
0x05 审查方法(REVIEW METHOD)
为了对 fuzzing 进行全面的调查, 作者遵循了一种系统的、结构化的方法。该方法受到了Kitchenham[20]和Webster and Watson[21]的指导方针的启发。在下述章节中,作者将详细介绍作者的研究方法、收集的数据和分析。
A. 研究问题(Research Question)
这篇调查主要目标是回答下列关于 fuzzing 的研究问题:
- RQ1: fuzzing 研究的关键问题和相应技术是什么?
- RQ2: 可用的 fuzzing 工具及其已知应用领域是什么?
- RQ3: 未来的研究机会或方向是什么?
RQ1在第八节中得到了回答,它允许我们深入探讨 fuzzing ,概述了自最初引入以来该领域的最新进展。第九节讨论 RQ2 旨在深入了解 fuzzing 的范围及其对不同领域的适用性。最后,根据前面问题的回答,在第十节中,作者希望确定 RQ3 中未解决的问题和研究机会。
B. 纳入和排除标准(Inclusion and Exclusion Criteria)
作者仔细阅读了现有文献,以找到与 fuzzing 各方面相关的论文,譬如方法、工具、对特定测试问题的应用、经验评估和调查。由相同作者撰写的内容相似的文章被有意分类并作为单独的贡献进行评估,以便进行更严格地分析。然后,作者对这些结果没有重大差异的文章进行分组。作者根据以下标准排除了这些论文:
- 与计算机科学领域无关的
- 非英文的
- 不是由著名出版商出版的
- 由知名出版商出版但不足6页的
- 无法通过网络访问的
例如,使用Wiley Interscience网站的关键字搜索界面,如fuzzing/fuzz testing/fuzzer,搜索到32篇论文,根据摘要描述,仅其中7篇与计算机科学领域相关。
C. 源材料及搜索策略(Source Material and Search Strategy)
为了提供涵盖所有与 fuzzing 相关的出版物的完整调查,作者通过三个步骤构建了一个 fuzzing 出版物存储库,其中包括 1990 年 1 月至 2017 年 6 月的 250 多篇论文。第一步,作者搜做了一些主要的在线存储库,如IEEE XPlore,ACM Digital Library,Springer Online Library,Wiley InterScience, USENIX 和 EIsevere ScienceDirect Online Library,并模拟收集了以“fuzz testing”,“fuzzing”,“fuzzer”,“random testing”,或“swarm testing”为关键词的论文标题、摘要或关键词。第二步,根据作者的选择标准,作者使用收集到的论文的摘要来排除其中的一些。 如果不能由摘要决定,确实通读了一篇论文。 这一步是由两位不同的作者进行的。 在作者的调查范围内,候选论文集减少到 171 篇出版物。 这些论文被称为初级研究[20]。 表 I 显示了从每个来源检索到的主要研究的数量。
表 I ——出版商和主要研究数量
| 出版商 | 主要研究数量 |
|---|---|
| ACM digital library | 33 |
| Elsevier Science Direct | 10 |
| IEEEXplore digital library | 87 |
| Springer online library | 17 |
| Wiley InterScience | 7 |
| USENIX | 11 |
| Semantic scholar | 6 |
| Total | 171 |
由于作者关注的是知名出版商的子集,因此作者的搜索仍有可能无法完全覆盖所有相关论文。 然而,作者相信本文中的总体趋势是准确的,并提供了 fuzzing 的最新技术水平。
D. 结果总结
以下部分总结了作者在模糊测试的出版趋势、地点、作者和地理分布方面的主要研究。
- 出版趋势:如图 1(a) 显示了1990年1月至2017年6月30日期间关于 fuzzing 的出版数量。图中显示,自2004年以来,特别是2009年只有,关于这一主题的论文数量不断增加。出版物的累积数量如图 1(b) 所示。作者计算了一个具有高决定系数 (R2=0.992) 的二次函数的紧密拟合,表明多项式增长强劲,表明对该主题的持续健康和兴趣。 如果这种趋势继续下去,到 2018 年底,也就是这项技术首次引入 30 年后,知名出版商将发表 200 多篇模糊测试论文。
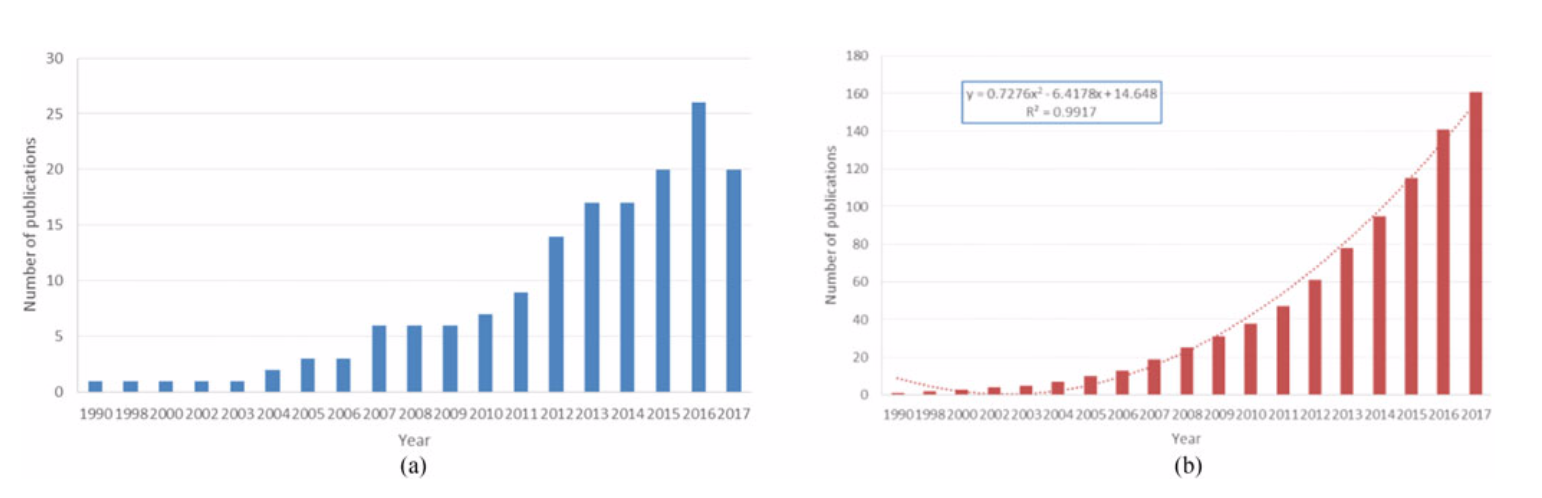
图 1——fuzzing 在1990年1月1日至2017年6月30日期间发表的论文。(a) 每年的出版物数量。(b) 每年的累计出版物数量。
-
出版地点:171项主要研究在78个不同的地点出版。这意味着 fuzzing 文献所涵盖的领域非常广泛。这可能是因为该技术非常实用,并已应用于多测试、可靠性和安全领域。就场地类型而言,大多数论文是在会议和座谈会上发表的(73%),其次是期刊(15%)、研讨会(9%)及技术报告(3%)。表 II 列出了至少提交了三份 fuzzing 论文的场所。
-
出版物的地理分布:作者将每项主要研究的地理来源与其第一共同作者的所属国家相关联。 有趣的是,作者发现所有 171 项主要研究都来自 22 个不同的国家,其中美国、中国和德国位居前三,如表 III 所示(仅限拥有超过四篇论文的国家)。按大洲来看,43% 的论文是 起源于美国,32% 来自欧洲,20% 来自亚洲,5% 来自大洋洲。 这表明 fuzzing 社区由数量适中的国家组成,但分布在世界各地。
-
研究人员与组织:作者在审查的 171 项主要研究中确定了 125 位不同的合著者。表 IV 列出了模糊测试的顶级作者及其最近的隶属关系。
表 II ——fuzzing的热门场所
| 场地 | 论文数 |
|---|---|
| Int. Conf. on Programming Language Design and Implementation (PLDD) | 12 |
| Int. Symposium on Software Testing and Analysis (ISSTA) | 9 |
| Int. Conf. on Software Engineering (ICSE) | 8 |
| Int. Conf. on Automated Software Engineering (ASE) | 7 |
| Int. Conf. on Software Testing, Verification & Validation (STVV) | 6 |
| USENIX Security Symposium (USENIX SEC.) | 5 |
| Workshop on Offensive Technologies(WOOT) | 5 |
| IEEE Transaction on Reliability (TRIEEE) | 4 |
| Network and Distributed System SecuritySymposium (NDSS) | 4 |
| ACM Conf. on Computer and Communicatons Security (CCS) | 4 |
| IEEE Symposium on Security and Privacy(S&P) | 3 |
| Communication of ACM (CACM) | 3 |
| ESEC/ACM Foundations of Software Engineering (FSE) | 3 |
| Security and Communication Networks(SCN) | 3 |
表 III ——出版物的地理分布
| 国家 | 论文数 |
|---|---|
| 美国 | 71 |
| 中国 | 17 |
| 德国 | 12 |
| 英国 | 9 |
| 法国 | 9 |
| 澳大利亚 | 9 |
| 瑞士 | 6 |
| 新加坡 | 5 |
| 荷兰 | 5 |
| 意大利 | 4 |
| 韩国 | 4 |
表 IV ——FUZZING 排名前 10 位的作者
| 作者 | 机构 | 论文数 |
|---|---|---|
| P. Godefroid | Microsoft Research | 9 |
| S. Rawat | Vrije Universiteit Amsterdam | 6 |
| T. Y. Chen | Swinburne University of Technology | 6 |
| A. Arcuri | Simula Research Laboratory | 4 |
| C. Cadar | Stanford University | 4 |
| A. Groce | Oregon State University | 4 |
| B. P.Miller | University of Wisconsin | 4 |
| Y. Chen | University of Utah | 3 |
| V.T. Pham | National University of Singapore | 3 |
| K. Sen | University of California | 3 |
0x06 模糊测试的一般过程(GENERAL PROCESS OF FUZZING)
Fuzzing 是一种软件测试技术,可以自动生成测试用例。 因此,我们在目标程序上运行这些测试用例,然后观察相应的程序行为,以确定目标程序中是否存在任何错误或漏洞。 模糊测试的一般过程如图2所示。
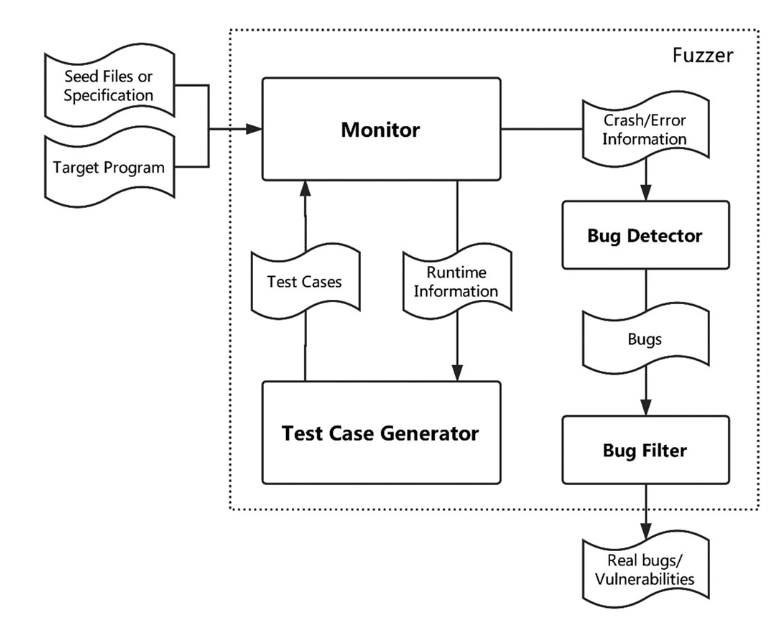
图 2 ——fuzzing 的一般过程
- 目标程序(Target program):目标程序是被测试的程序。它可以是二进制代码或源代码。 然而,现实世界软件的源代码通常不容易访问,因此 fuzzer 通常针对二进制代码。
- 监视器(Monitor):该组件通常内置于白盒或灰盒 fuzzer 中。 监视器利用代码检测、污点分析等技术来获取目标程序的代码覆盖率、污点数据流或其他有用的运行时信息。 黑盒 fuzzer 中不需要监视器。
- 测试用例生成器(Test case generator):模糊器生成测试用例的主要方法有两种:基于变异的方法和基于语法的[1]方法。 第一种方法通过随机变异格式良好的种子文件或使用预定义的变异策略来生成测试输入,这些策略可以根据运行时收集的面向目标程序的信息进行调整。 相反,第二种方法不需要任何种子文件。 它从规范(例如,语法)生成输入。 在很多情况下,fuzzing 中的测试用例通常是半有效的输入,它们足够有效以通过早期解析阶段,并且足够有效以触发目标程序深层逻辑中的错误。
- Bug检测器(Bug detector):为了帮助用户发现目标程序中的潜在错误,在模糊器中设计并实现了错误检测器模块。 当目标程序崩溃或报告一些错误时,错误检测器模块收集并分析相关信息(例如,堆栈跟踪 [22])以确定是否存在bug。 有时,可以手动使用调试器来记录异常信息 [23]-[25] 作为此模块的替代方案。
- Bug过滤器(Bug filter):测试人员通常关注正确性或与安全相关的错误。 因此,从所有报告的错误中过滤可利用的错误(即漏洞)是一项重要的任务,通常需要手动执行 [23],这不仅耗时而且难以解决。 目前,一些研究工作 [26] 提出了各种方法来缓解这个问题。例如,通过对 fuzzer 的输出进行排序(导致 bug 的测试用例),优先考虑多样化、有趣的测试用例,测试人员不需要像大海捞针一样手动搜索想要的 bug。
为了更清楚地解释模糊测试的过程,以 American fuzzy lop (AFL) [27]——一种基于突变的覆盖引导模糊器为例,来测试 png2swf(一种文件转换器)。在本例中,作者为 AFL 提供了 png2swf 可执行文件作为其目标程序。首先,作者为 AFL 提供了一些种子文件(理想的种子应该是结构良好且尺寸小),因为它采用了基于突变的技术。其次,作者通过一个简单的命令运行 AFL(例如,afl-fuzz -i [input_directory] -o [output_directory] -Q –[target_directory](@@)”,如果目标程序从文件中获取输入,则“@@ “ 是必要的)。在测试过程中,AFL 的“监视器”组件通过二进制检测收集特定的运行时信息(在本例中为路径覆盖信息),然后将这些信息传递给“测试用例生成器”组件以帮助指导其测试用例生成过程。一般的策略是保存那些能够覆盖下一轮变异的新程序路径的测试用例,否则丢弃那些测试用例。第三,将新生成的测试用例作为目标程序的输入传回“监视器”。这个过程一直持续到我们停止 AFL 实例或达到给定的时间限制。此外,AFL 还会在运行时在屏幕上打印一些有用的信息,例如执行时间、唯一崩溃次数、执行速度等。因此,我们可能会得到一组可以使目标程序崩溃的测试用例。最后,我们分析测试用例并识别那些手动或借助其他工具使目标程序崩溃的错误。 AFL发现的bug主要与内存操作有关,如缓冲区溢出、访问冲突、堆栈粉碎等,通常会导致程序崩溃或被黑客利用。
0x07 黑盒、白盒或灰盒?(BLACK, WHITE, OR GRAY?)
Fuzzing 技术可以分为三种:黑盒、白盒和灰盒,这取决于它们在运行时需要从目标程序获得多少信息 [28]。 信息可以是代码覆盖率、数据流覆盖率、程序的内存使用率、CPU 使用率或任何其他指导测试用例生成的信息。
A. 黑盒 Fuzzing
传统的黑盒模糊测试也被称为“黑盒随机测试”。 黑盒随机测试不需要来自目标程序或输入格式的任何信息,而是使用一些预定义的规则来随机变异给定的格式良好的种子文件以创建格式错误的输入。 变异规则可以是位翻转、字节复制或字节删除 [28] 等。最近的黑盒模糊测试还利用语法 [29] 或输入特定知识 [30] 来生成半有效的输入。
黑盒模糊测试,例如 fuzz [ 31] 和 Trinity [32],由于其在发现错误和使用简单方面的有效性而在软件行业中很受欢迎。 例如,Trinity 旨在模糊 Linux 内核的系统调用接口。 测试人员应首先使用提供的模板来描述输入的类型。然后,Trinity 可以生成更多有效输入,从而达到更高的覆盖率。 这个 fuzzer 发现了很多错误。
然而,这种技术的缺点也很明显。考虑图 3 所示的函数。当第 1 行的输入参数被随机分配时,第 7 行的 abort() 函数只有 1/232 机会达到。 这个例子直观地解释了为什么黑盒模糊测试很难生成覆盖目标程序中大量路径的测试用例。 由于这种盲目性,黑盒模糊测试通常在实践中提供低代码覆盖率 [33]。 这就是为什么最近的模糊器开发人员主要关注逆向工程 [34]、代码检测 [35]、污点分析 [23]、[36]、[37] 以及其他使模糊器“更智能”的技术,以减轻这种情况 问题,这就是为什么白盒和灰盒模糊测试最近受到更多关注的原因。
void test (char input[4]) {
int count = 0;
if( input[0] == 'o') count++;
if( input[1] == 'o') count++;
if( input[2] == 'p') count++;
if( input[3] == 's') count++;
if(count == 4) abort(); // error
}
图 3 ——示例程序
B. 白盒 Fuzzing
白盒模糊测试基于目标程序内部逻辑的信息[17]。它使用一种理论上可以探索目标程序中所有执行路径的方法。它是由 Godefroidet al.[38] 首次提出的。为了克服黑盒模糊测试的盲目性,他们致力于探索另一种方法并将其称为白盒模糊测试[14]。通过使用动态符号执行(也称为 concolic 执行 [39])和覆盖最大化启发式搜索算法,白盒模糊测试可以彻底快速地搜索目标程序。
与黑盒模糊测试不同,白盒模糊测试需要来自目标程序的信息,并使用所需的信息来指导测试用例的生成。具体来说,从给定的具体输入开始执行,白盒模糊器首先在输入下沿执行路径的所有条件语句上收集符号约束。因此,执行一次后,白盒模糊器使用逻辑与将所有符号约束组合在一起,形成路径约束(简称PC)。然后,白盒模糊器系统地否定了其中一个约束并解决了新 PC。新的测试用例导致程序运行不同的执行路径。使用覆盖最大化启发式搜索算法,白盒模糊器可以尽快找到目标程序中的错误[38]。
理论上,白盒模糊测试可以生成覆盖所有程序路径的测试用例。然而,在实践中,由于实际软件系统中执行路径众多,符号执行过程中求解约束不精确(详见0x08-B部分)等诸多问题,白盒模糊测试的代码覆盖率无法实现100%。最著名的白盒模糊器之一是 SAGE [14]。 SAGE 以大规模 Windows 应用程序为目标,并使用多项优化来处理大量执行跟踪。它可以自动发现软件错误并取得了令人瞩目的成果。
C. 灰盒 Fuzzing
灰盒 fuzzing 介于黑盒 fuzzing 和白盒 fuzzing 之间,可以有效地揭示对目标程序有部分了解的软件错误。灰盒模糊测试中常用的方法是代码插装[40]、[41]。通过这种方式,灰盒模糊测试可以在运行时获取目标程序的代码覆盖率;然后,它利用这些信息来调整(例如,通过使用遗传算法 [28]、[42])其突变策略来创建可能覆盖更多执行路径或更快发现错误的测试用例。灰盒模糊测试中使用的另一种方法是污点分析 [23]、[43]-[45],它扩展了用于跟踪污点数据流的代码检测。因此,模糊器可以专注于改变输入的特定字段,这些字段可以影响目标程序中的潜在攻击点。
灰盒和白盒模糊测试非常相似,这两种方法都利用目标程序的信息来指导测试用例的生成。但它们之间也有一个明显的区别:灰盒模糊测试仅利用目标程序的一些运行时信息(例如,代码覆盖率、污点数据流等)来决定探索了哪些路径 [28]。此外,灰盒模糊测试仅使用获取的信息来指导测试用例生成,但不能保证使用这条信息一定会生成更好的测试用例来覆盖新路径或触发特定错误。相比之下,白盒模糊测试利用目标程序的源代码或二进制代码来系统地探索所有执行路径。通过使用动态执行和约束求解器,白盒模糊测试可以确保生成的测试用例将引导目标程序探索新的执行路径。因此,白盒模糊测试有助于更彻底地降低模糊测试过程中的盲目性。 总之,两种方法都利用目标程序的信息来减轻黑盒模糊测试的盲目性,但程度不同。
BuzzFuzz [46]是一个很好的展示灰盒模糊器如何工作的示例,尽管 BuzzFuzz 的开发人员称其为白盒模糊器。我们将此工具视为灰盒模糊器,因为它仅获取目标程序的部分知识(污点数据流)。 BuzzFuzz 的工作原理如下。首先,它检测目标程序以跟踪受污染的格式良好的输入数据。然后,根据收集到的污点传播信息,计算输入数据的哪些部分可能会影响预定义的攻击点(BuzzFuzz 将 lib 调用视为目标程序中的潜在攻击点)。接下来,它对输入数据的敏感部分进行变异以创建新的测试用例。最后,它执行新的测试用例,观察目标程序是否崩溃。通过这种方式,BuzzFuzz 可以更面向目标和有效的方式发现错误。更重要的是,攻击点可以定义为特定的库调用,或者漏洞模式等,取决于开发人员的关注。
D. 如何选择?
根据被触发或发现的可能性,Bug 可以分为两类:“浅层”Bug 和“隐藏”Bug。在执行的早期阶段导致目标程序崩溃的错误被视为“浅”bug,例如,没有任何先决条件分支的潜在除零操作。反之,程序逻辑深处存在的、难以触发的bug则被视为“隐藏”bug,比如存在于复杂条件分支中的bug。没有标准的方法来识别“浅”和“隐藏”的错误;因此,模糊器的常用评估标准是它实现的代码覆盖率、它发现的错误的数量和可利用性。一般来说,传统的黑盒模糊器仅使用随机变异的方法生成测试用例,无法达到高代码覆盖率,因此通常会发现浅层错误;但是,它轻巧、快速且易于使用。相比之下,白盒或灰盒 fuzzer 可以实现更高的代码覆盖率,并且通常比黑盒 fuzzers 发现更多隐藏的错误,但这些 fuzzer 构建起来更复杂,而且模糊过程比黑盒 fuzzers 更耗时。
使用简单的变异方法通常被认为是“哑的”模糊测试,例如 Charlie Miller 使用的著名的“5-lines of Python”方法,它只随机变异输入文件的某些字节,而不知道其格式。相反,那些利用输入规范或其他知识或采用运行时信息(例如,路径覆盖)来指导测试用例生成的技术通常被认为是“智能”模糊测试。一般来说,“哑”和“智能”模糊测试方法提供不同的成本/精度权衡,适用于不同的情况。对于测试人员来说,选择哪种fuzzer主要取决于两个因素:1)目标程序的类型和2)测试要求(时间/成本等)。如果目标程序的输入格式(例如编译器、系统调用、网络协议等)是特定的或严格的,选择基于语法的模糊器会更有效(这种模糊器很多是黑盒,例如 Trin-ity [32],但开发人员最近构建了针对此类软件的灰盒模糊器,例如 Syzkaller [15])。在其他情况下,测试人员应该更多地考虑测试要求。如果测试的主要目标是效率而不是精度或高质量输出,那么黑盒模糊测试将是一个不错的选择。例如,如果一个软件系统之前没有经过测试,而测试人员希望尽快找到并消除“浅层”错误,那么黑盒模糊测试就是一个好的开始。相反,如果测试人员更关注输出的质量(即发现的错误的种类、可利用性和数量)并希望实现更高的代码覆盖率,则灰盒(有时是白盒)模糊测试通常更多合适 [14]。 与灰盒fuzzing相比,白盒 fuzzing在工业上不是很实用(虽然SAGE是市场上有名的白盒fuzzer),因为这种技术非常昂贵(耗时/资源消耗)并且面临许多挑战(例如路径爆炸 、内存建模、约束求解等)。 然而,白盒模糊测试是一个具有很大潜力的流行研究方向。
0x08 模糊测试的最新技术(STATE OF THE ART IN FUZZING)
根据0x06中描述的模糊测试的一般过程,在构建 fuzzer 时应考虑以下问题:
- 如何生成或选择种子和其他测试用例
- 如何根据目标程序的规范验证这些输入
- 如何处理那些导致崩溃的测试用例
- 如何利用运行时信息
- 如何提高模糊测试的可扩展性
在本节中,我们通过总结文献中上述五个模糊测试问题的主要贡献来解决 RQ1。0x08-A 节中与种子生成和选择相关的论文,0x08-B 节讲述输入验证和覆盖率,0x08-C 节讲述运行时信息和有效性,0x08-D 节讲述崩溃诱导测试用例处理,以及0x08-E 节中的可扩展性注入。
A. 种子生成与选择(Seeds Generation and Selection)
给定一个要fuzz的目标程序,测试者首先需要找到输入接口(例如stdin文件),以便目标程序可以从文件中读取,然后确定目标程序可以接受的文件格式,然后选择收集到的种子文件的子集来 fuzz 目标程序。 种子文件的质量可能会极大地影响模糊测试的结果。 因此,如何生成或选择合适的种子文件以发现更多的错误是一个重要的问题。
一些研究工作已经进行了解决这个问题。 Rebert等人 [47] 测试了六种选择算法:
- 来自Peach的集合覆盖算法
- 随机种子选择算法
- 最小集合覆盖(同minset,可以用贪心算法计算)
- 最小集合覆盖大小加权
- 一个由执行时间加权的最小集合覆盖
- 一个热集算法(它对每个种子文件进行 fuzz 几秒钟的模糊测试,按唯一发现的错误数量对它们进行排名,并返回列表中的前几个种子文件)
通过在 Amazon Elastic ComputeCloud 上花费 650 个 CPU 天对 10 个应用程序进行模糊测试,他们得出了以下结论。
- 采用启发式算法的算法比完全随机采样的算法表现更好
- 未加权的 minset 算法在这六种算法中表现最好
- 在实践中,减少的种子文件集比原始文件集的执行效率更高
- 减少的种子文件集可以应用于解析相同文件类型的不同应用程序
Kargen 和 Shahmehri [48] 声称通过对生成程序的机器代码执行变异而不是直接在格式良好的输入上执行变异,生成的测试输入更接近被测程序预期的格式,从而产生更好的代码覆盖率。为了测试通常采用嵌入多个对象(例如字体、图片)的各种输入的复杂软件(例如 PDF 阅读器),Lianget 等人[49]利用字体文件的结构信息在异构字体中选择种子文件。 Skyfire [50] 将语料库和语法作为输入,并使用大量现有样本中的知识为处理高度结构化输入的模糊测试程序生成分布良好的种子输入。 [51] 中提出了一种算法,在给定程序和 aseed 输入的情况下,最大化黑盒突变模糊测试发现的错误数量。这背后的主要思想是利用对给定程序种子对的执行轨迹的白盒符号分析来检测输入的位位置之间的依赖关系,然后使用这种依赖关系来计算概率上的最优变异率。程序种子对。此外,将模糊测试视为概率分析中优惠券收集器问题的一个实例,Arcuriet 等人[52] 提出并证明了通过随机测试采样的预期测试用例数量的非平凡的最佳下限,以覆盖预定义的目标,尽管没有给出如何在实践中实现边界目标。
对于随机生成面向对象程序的单元测试,Pachecoet等人[53] 建议使用在构建序列时从执行序列中获得的反馈,以引导搜索产生新的和合法的对象状态的序列。因此,永远不会扩展创建冗余或非法状态的输入。然而,Yatohet等人 [54]认为反馈引导可能会过度指导生成并限制生成测试的多样性,并提出了一种名为反馈控制随机测试的算法,该算法自适应地控制反馈量。
我们如何首先获得原始种子文件?对于一些开源项目,应用程序发布时有大量的输入数据进行测试,可以免费获取作为模糊测试的优质种子。例如,FFmpeg 自动化测试环境(FATE)[55] 提供了各种测试用例,这些测试用例很难靠测试人员自己的力量收集。有时,测试数据不公开,但开发人员愿意与愿意交换的人交换。作为回报报告程序错误。其他一些开源项目也提供格式转换器。因此,对于一定格式的各种文件集,测试者可以通过使用格式转换器获得不错的种子进行模糊测试。例如,cwebp [56] 可以将 TIFF/JPEG/PNG 转换为 WEBP 图像。此外,逆向工程有助于为模糊测试提供种子输入。 Prospex [57] 可以提取网络协议规范,包括协议状态机,并使用它们自动生成状态模糊器的输入。自适应随机测试 (ART) [58] 通过对测试空间进行采样并仅执行那些最远的测试来修改随机测试,这由距离度量过度输入确定,来自所有先前执行的测试。 ART 并不总是被证明对复杂的现实世界程序有效[59],并且主要应用于数字输入程序。
与上述方法相比,通过爬行互联网收集种子文件更为普遍。测试人员可以根据特定字符(例如文件扩展名、魔术字节等)下载所需的种子文件。如果收集的语料库很大,这不是一个严重的问题,因为存储便宜并且语料库可以压缩到更小的尺寸,同时达到等效的代码覆盖率[60]。为了减少错误插入文件的数量并保持最大的测试用例覆盖率,Kimet等人 [61] 建议通过跟踪和分析堆栈帧、汇编代码和寄存器来分析二进制文件的字段,因为目标软件解析文件。
B. 输入验证和覆盖率(Input Validation and Coverage)
自动生成大量测试用例来触发目标程序的意外行为的能力是模糊测试的一个显着优势。 但是,如果目标程序有输入验证机制,这些测试用例很可能在执行的早期阶段就被拒绝。 因此,当测试人员开始使用这种机制对程序进行 fuzz 时,如何克服这个障碍是一个必要的考虑。
- 完整性验证:在传输和存储过程中,原始数据可能会引入错误。为了检测这些“失真”的数据,校验和机制通常用于某些文件格式(如PNG)和网络协议(如TCP/IP)中,以验证其输入数据的完整性。使用校验和算法(例如,哈希函数),原始数据附有唯一的校验和值。对于数据接收方,可以通过使用相同的算法重新计算校验和值并将其与附加的进行比较来验证接收数据的完整性。为了对这种系统进行 fuzz,需要在 fuzzer 中加入额外的逻辑,以便计算新创建的测试用例的正确校验和值。否则,开发人员必须使用其他方法来消除这个障碍。Wang等人[36]、[62] 提出了一种解决这个问题的新方法,并开发了一个名为 TaintScope 的 fuzzer。TaintScope 首先使用动态污点分析和预定义规则来检测可能污染目标中敏感应用程序编程接口 (API) 的潜在校验和点和热输入字节程序。然后,它改变热字节以创建新的测试用例并更改校验和点,让所有创建的测试用例通过完整性验证。最后,它通过符号执行和约束求解来修复那些可能使目标程序崩溃的测试用例的校验和值。通过这种方式,它可以创建既可以通过完整性验证又可以导致程序崩溃的测试用例。
给定一组样本输入,H ̈oschele 和 Zeller [63] 使用动态污染来跟踪每个输入字符的数据流,并将这些输入片段聚合为词汇和句法实体。 结果是上下文无关语法,反映了有效输入结构,这有助于后面的模糊测试过程。为了减轻基于覆盖的模糊器在使用魔术字节比较保护的路径方面的限制,Steilix [64] 利用轻量级静态分析和二进制仪器来提供覆盖信息、与 fuzzer 的比较进度信息。 这样的程序状态信息通知模糊器关于魔法字节在测试输入中的位置以及如何执行突变以有效地匹配魔法字节。 还有一些其他的努力 [65]、[66],在缓解这个问题方面取得了进展。
-
格式验证:网络协议、编译器、解释器等,对输入格式有严格要求。不符合格式要求的输入将在程序执行开始时被拒绝。因此,对这种目标系统进行模糊测试需要额外的技术来生成可以通过格式验证的测试用例。该问题的大多数解决方案是利用输入特定知识或语法。Ruiter 和 Poll [30] 通过使用黑盒模糊测试与状态机学习相结合,评估了九种常用的传输层安全 (TLS) 协议实现。他们提供了一个抽象消息列表(也称为输入字母表),测试工具可以将这些消息转换为发送到被测系统的具体消息。Dewey等人[67], [68] 提出了一种通过约束逻辑编程 (CLP) 生成使用复杂类型系统的类型良好程序的新方法,并将其应用于生成 Rust 或 JavaScript 程序。Cao等人[69]首先调查了Android系统服务的输入验证情况,并为Android设备构建了一个输入验证漏洞扫描器。这个扫描器可以创建半有效的参数,这些参数可以通过目标系统服务的方法实现的初步检查。还有一些其他的工作,例如 [24]、[25]、[70] 和 [71],专注于解决这个问题。
-
环境验证:只有在特定环境(即特定配置、特定运行时状态/条件等)下,许多软件漏洞才会暴露出来。 典型的模糊测试不能保证输入的句法和语义有效性,或探索输入空间的百分比。 为了缓解这些问题,Daiet等人 [72] 提出了配置模糊测试技术,其中正在运行的应用程序的配置在某些执行点发生变异,以检查仅在某些条件下出现的漏洞。 FuzzDroid [73] 还可以自动生成一个 Android 执行环境,其中应用程序会暴露其恶意行为。 FuzzDroid 通过基于搜索的算法结合了一组可扩展的静态和动态分析,将应用程序引导至可配置的目标位置。
-
输入覆盖范围:Tsankovet 等人[74] 定义了半有效输入覆盖(SVCov),这是模糊测试的第一个覆盖标准。只要有效输入可以由一组有限的约束来定义,该标准就适用。通过增加 SVCov 下的覆盖率,他们发现了成熟的 Internet 密钥交换 (IKE) 实现中以前未知的漏洞。为了解决现有语法推理算法严重缓慢和过度泛化的缺点,Bastani等人 [75] 提出了一种算法,用于从一组输入示例和对程序的黑盒访问中合成编码有效程序输入语言的上下文无关语法。与许多通过目标程序崩溃来确定输入是否有效的方法不同,ArtFuzz[76] 旨在捕捉非崩溃缓冲区溢出漏洞。它利用类型信息并动态发现可能的内存布局来帮助模糊测试过程。如果超出了从内存布局中识别出的缓冲区边界,则会报错。
考虑到多样性的增加会导致覆盖率和故障检测的改善,Groceet 等人[77] 提出了一种低成本且有效的方法,称为群测试,以增加(随机生成的)测试用例的多样性,它使用不同的测试配置群,每个测试配置都故意省略某些 API 调用或输入功能。 此外,为了减轻无法专注于被测系统的一部分,定向群测试 [78] 利用群测试并记录过去测试结果的统计数据来生成针对任何给定源代码元素的新随机测试。 根据观察,开发人员有时会在提交的补丁中附上部分执行新代码的测试用例,并且这个测试用例可以很容易地用作符号探索的起点,Marinescu 和 Cadar [79] 提供了一种自动生成测试套件的方法,实现软件补丁的高覆盖率。
C. 处理引发崩溃的测试用例(Handling Crash-Inducing Test Cases)
软件公司(例如 Microsoft)和开源项目(例如 Linux)经常使用模糊测试来提高其产品的质量和可靠性 [17]。尽管模糊测试擅长生成引发崩溃的测试用例,但它通常不够聪明,无法自动分析这些测试用例的重要性。如果模糊测试导致一堆原始的崩溃诱导测试用例,测试人员需要花费大量时间通过分析这些测试用例来找到目标程序中的不同错误。由于时间或预算限制,开发人员更喜欢修复那些严重的错误。
目前,只有少数工作专注于如何过滤原始模糊测试输出,使模糊测试结果对测试人员更有用。给定大量测试用例,每个测试用例都可以触发程序bug,Chen等人 [26] 提出了一种基于排名的方法,通过该方法将引起不同错误的测试用例放在列表的顶部。与传统的聚类方法[80]、[81]相比,这种基于排名的方法更实用。因此,测试人员可以专注于分析最容易引发崩溃的测试用例。除了直接过滤引发崩溃的测试用例外,还有一些其他方法可以帮助减少昂贵的人工工作,例如生成独特的引发崩溃的测试用例、修剪测试用例以及提供有用的调试信息。
导致崩溃的测试用例的唯一性可以由目标线程的调用堆栈和导致故障的指令的地址可靠地确定[82]。 如果两个不同的测试用例导致目标程序因调用堆栈相同而崩溃,则这两个测试用例很可能对应同一个错误; 因此,只需要保留其中一个用于手动分析。 相反,如果它们导致目标程序在同一位置崩溃但具有不同的堆栈跟踪,则它们很可能对应于两个不同的错误,因此它们都值得分别分析。与记录调用堆栈相比,跟踪执行路径是一种更简单但不太可靠的确定唯一性的方法。 AFL [27] 是最流行的 fuzzer 之一,如果找到新路径或未找到公共路径,则将引发崩溃的测试用例视为唯一。这种易于实现的方法类似于执行路径记录方法,它是AFL的基础。生成独特的引发崩溃的测试用例可以帮助减少冗余的模糊测试输出,从而可以节省人工分析的时间和精力。
测试用例的大小会极大地影响人工分析的效率,因为更大的测试用例需要花费更多的时间来执行和定位导致故障的指令。 对于基于变异的模糊器,如果使用低质量的种子文件,可以在某些变异方法下迭代增加生成的测试用例的大小。 因此,在fuzzing过程中,定期对生成的测试用例进行修整,可以提高整体效率,从而减少人工分析碰撞诱发测试用例的工作量。 修剪的原则很简单:处理后的行为应该与原始行为相同; 换句话说,它们应该遵循相同的执行路径。 修剪的一般步骤是从测试用例中依次删除数据块并重新评估测试用例的其余部分; 那些不能影响执行路径的数据块将被修剪。
评估模糊测试输出的可利用性通常需要代码分析和调试工作,这些工作可以从 GDB、Valgrind [41]、AddressSanitizer[83] 等专用工具中受益。这些工具提供运行时上下文(例如,调用堆栈状态和 目标程序的寄存器、故障诱导指令的地址等)或可以检测特定类型的程序故障,如内存错误。 在他们的帮助下,测试人员能够更有效地发现和评估程序错误。此外,Phamet 等人[84] 提出了一种生成到达给定“潜在崩溃”位置的输入的方法。 他们的方法生成的测试输入作为崩溃的见证。
D. 利用运行时信息(Leveraging Runtime Information)
作为两种流行的程序分析技术,符号执行和动态污点分析经常被用来使模糊测试变得智能,因为它们可以提供很多运行时信息(例如代码覆盖率、污点数据流)并帮助模糊测试找到“隐藏”错误[85 ],[86]。 然而,它们的问题也阻碍了模糊测试追求更高的效率[87]。 在本节中,我们将讨论路径爆炸、混合执行和欠污染面临的不精确符号执行以及动态污点分析面临的覆盖等问题,并总结相应的解决方案。 了解它们可以帮助读者更深入地了解 smartfuzzing。
-
路径爆炸:路径爆炸是符号执行中一个固有的最彻底的问题,因为目标程序中的条件分支通常非常多,即使是小规模的应用程序也会产生大量的执行路径。
从程序分析方法和路径搜索算法方面,一些研究试图缓解这个问题。例如,使用函数摘要[88]、[89]来描述低级函数的属性,以便高级函数可以重用它们以减少执行路径的数量。 冗余路径修剪用于避免执行那些与一些先前覆盖的路径具有相同副作用的路径。例如,Boonstoppelet 等人[90] 提出了一种通过跟踪目标程序执行的读写操作来检测和丢弃大量冗余路径的技术。 该技术背后的主要思想是,如果一条路径在与一些先前探索的路径相同的条件下到达程序点,则可以修剪导致相同后续效果的路径。 此外,合并不同路径上获得的状态[91]也可以减少路径搜索空间,但这种方法加重了求解器的负担。
另一方面,启发式搜索算法可以在有限的时间内尽快探索最相关的执行路径。例如,随机路径选择 [92] 和自动部分循环总结 [93] 在实践中被证明是成功的,主要是因为它们在遇到一些可以快速创建新状态的紧密循环时避免卡住。另一个例子是控制流图(CFG)导向的路径选择[94],它利用静态控制流图来引导测试用例生成以探索最近的未覆盖分支。实验表明,这种贪婪的方法可以帮助更快地提高覆盖率并实现更高百分比的代码覆盖率。此外,还有分代搜索[38],它探索每个扩展执行的所有子路径,对它们进行评分,最后选择一条路径下次执行的最高分。考虑到现有的基于覆盖的灰盒模糊测试工具访问了高密度区域的太多状态; B ̈ohmeet 等人[95] 提出并实施了几种策略,以迫使 AFL [27] 通过访问更多隐藏在低密度区域中的状态来为高密度区域中的状态生成更少的输入。为了缓解路径爆炸问题,DeepFuzz [96] 为执行路径分配了概率,并应用了一种新的搜索启发式方法,可以有效地将路径爆炸延迟到测试二进制文件的更深层。给定一套现有的测试用例,Zhang等人 [97] 利用测试用例减少和优先级方法来提高种子符号执行的效率,目标是尽快获得增量覆盖。
-
不精确的符号执行:符号执行的不精确主要是由复杂的程序结构(例如,指针)建模、库或系统调用和约束求解引起的。 为了使符号执行变得可行,需要在上述领域进行一些简化方法。 因此,开发者的重点是在可扩展性和精度之间找到一个平衡点。
目前,已经提出了一些方法,以牺牲精度为代价使符号执行更加实用。 CUTE[98]对指针的操作进行了简化,在处理符号指针变量时只考虑相等和不等谓词。 在KLEE [92] 中,指针被视为数组。 KLEE将当前状态复制N次,当一个指针p间接指向N个对象时,在每个状态下,在p不超出对应对象边界的前提下,执行适当的读或写操作。无法访问源代码的库或系统调用站点将使用具体值而不是库中的符号值 [99]。 此外,约束求解加入了大量约束优化[100](例如,SAGE使用无关约束消除、局部约束缓存、翻转计数限制等,以提高生成约束时的内存使用和速度)甚至输入语法( 例如,Godefroidet 等人[36] 提出了一种方法,通过该方法可以通过符号执行直接生成基于输入语法的约束。然后,这些约束的可满足性将通过同样利用输入语法的定制约束求解器来验证。因此,它可以生成高度结构化的输入 )。
为了 fuzzing 可能导致符号执行不精确的浮点 (FP, floating-point) 代码,Godefroid 和 Kinder [102] 将 FP 指令的轻量级局部路径不敏感“可能”静态分析与高精度的整体程序路径相结合。 非 FP 指令的敏感“必须”动态分析。 Fu 和 Su [103] 将测试 FP 代码的挑战转化为应用无约束编程的机会——在整个搜索空间计算函数最小点的数学解决方案。 他们从 FP 代码中导出了一个表示函数,其中任何一个最小点都是一个测试输入,保证执行被测试程序的一个新分支。
-
欠污染:当隐式数据流中的数据传输与控制流、数组操作等相关联时,就会发生欠污染。 如图 4 所示,在纯文本格式到富文本格式的转换过程中,输入变量的值被转入输出数组,无需直接赋值。 因此,如果输入被污染,忽略这个隐式数据流将导致污染。Kang等人 [44]在解决这个问题上取得了进展。 根据他们的实验,所有隐式流的污点传播也会导致不可接受的污染过度。 因此,他们只关注完整信息保留隐式流的污点传播,如图 4 所示。
if (input == '{') { output[0] = '\'; output[1] = '{'; len = 2 } else if(...) { ... }图 4 ——显示隐式数据流的代码片段
-
过度污染:当污点传播没有以更细粒度的粒度实现时,就会发生过度污染。 它会导致污染爆炸和误报。 Yadegari 等人 [104] 提出了一种在位级实现污点传播的方法来缓解这个问题。 处理此问题的另一种方法是使用欠近似来检查存在的“某些路径”属性。Godefroid[89]提出了一种新的测试生成方法,其中测试源自一阶逻辑公式的有效性证明,而不是像大多数当前方法那样满足无量词一阶逻辑公式的赋值。有关符号执行和污染分析的更多详细信息,参考专业文献[39]、[105]。
E. Fuzzing 的可扩展性(Scalability in Fuzzing)
面对现实世界应用程序的规模和复杂性,现代 fuzzer 往往要么可扩展但不能有效地探索位于目标程序更深处的错误,要么不可扩展但能够深入应用程序。Arcuriet 等人 [106] 讨论了模糊测试的可扩展性,在某些条件下,它可以比一大类分区测试技术更好。
Bounimova 等人 [107] 报告了从 2007 年到 2013 年在数百个大型 Windows 应用程序和超过 500 个机器年计算的生产中基于约束的白盒模糊测试的经验。他们使用日志记录和控制机制扩展了 SAGE,以管理数百个不同应用程序配置的多月部署 。他们声称他们的工作是白盒模糊测试的首次生产使用,也是迄今为止白盒模糊测试的最大规模部署。
一些方法利用应用程序感知模糊测试或通过云服务方法进行模糊测试来解决此问题。 Rawat 等人 [108] 提出了一种应用程序感知进化模糊策略,它不需要任何应用程序或输入格式的先验知识。 为了最大化覆盖范围并探索更深的路径,他们利用基于静态和动态分析的控制和数据流功能来推断应用程序的基本属性,与应用程序无关的方法相比,这能够更快地生成有趣的输入。
一种提高可扩展性的方法是缩小分析范围。 回归分析是一个众所周知的例子,其中程序版本之间的差异作为缩小分析范围的基础。 DiSE [109] 结合了两个阶段:静态分析和符号执行。 受影响的程序指令集在第一阶段生成。 静态分析生成的信息然后用于指导符号执行以仅探索受更改影响的程序部分,从而潜在地避免了大量未受影响的执行路径。
为了以可扩展的方式测试移动应用程序,每个测试输入都需要在各种环境下运行,例如:设备异构、无线网络速度、位置和不可预测的传感器输入。 每个上下文(例如位置)的值范围可能非常大。 Liang 等人 [110] 提出了 Caiipa,这是一种云服务,用于以可扩展的方式在扩展的移动上下文空间上测试应用程序,并在虚拟机集群和真实设备上实现,可以模拟移动应用程序的各种上下文组合。 移动漏洞发现管道(MVDP)[111] 也是适用于 Android 和 iOS 设备的分布式黑盒模糊测试系统。
0x09 不同应用领域的工具(TOOLS IN DIFFERENT APPLICATION AREAS)
Fuzzing 是一种实用的软件测试技术,在工业中得到了广泛的应用。 任何接受用户输入的软件都可以被视为模糊测试目标。 目前,有针对不同软件系统的各种模糊器。 在本节中,我们通过调查按应用领域(即目标软件平台的类型)分类的一些最流行和最高效的模糊器来回答 RQ2。 表 V 和 VI 分别总结了我们将要介绍的典型模糊器,分别来自应用领域和问题领域。
表 V ——典型 fuzzer 概述
| 名称 | 出现年份 | 目标类型 | 关键技术 | 平台 | 可用性 |
|---|---|---|---|---|---|
| Peach | 2004 | 一般用途 | 黑盒变异/生成 fuzzing | Linux, Windows, MacOS |
开源 |
| Trinity | 2004 | 操作系统内核 | 基于输入知识的黑盒生成模糊测试 | ARM, i386,x86-64等 | 开源 |
| beSTORM | 2005 | 一般用途 | 黑盒生成模糊测试 | Linux, Windows |
商用 |
| isfunfuzz | 2007 | Firefox JavaScript引擎 | 基于语法的黑盒生成模糊测试,差异测试 | Linux, Windows, MacOS |
开源 |
| SAGE | 2008 | 大型Windows应用 | 白盒生成模糊测试 | Windows | 微软内部 |
| Sulley | 2009 | 网络协议 | 基于输入知识的黑盒生成模糊测试 | Windows | 开源 |
| IOCTL fuzzer | 2009 | 内核驱动程序 | 基于输入知识的黑盒生成模糊测试 | Windows | 开源 |
| Csmith | 2011 | C 编译器 | 基于语法的黑盒生成模糊测试,差异测试 | Linux, Free BSD, Windows, MacOS |
开源 |
| LangFuzz | 2012 | 未知语言解释器(JavaScript, PHP) | 基于语法的黑盒生成/变异模糊测试 | Linux | 闭源 |
| AFL | 2013 | 应用程序 | 覆盖为导向的灰盒模糊测试,遗传算法 | Linux, Free-/Open-/NetBSD, MacOS, Solaris | 开源 |
| YMIR | 2013 | ActiveX 控件 | 使用 API 生成模糊语法水平锥度测试 | Windows | 闭源 |
| vUSBf | 2014 | USB 驱动 | 基于输入知识的黑盒生成模糊测试 | Linux | 开源 |
| CLsmith | 2015 | 许多核心的 openCL 编译器 | 基于语法的黑盒生成模糊测试,随机差分测试和 EMI 测试 | Linux | 开源 |
| Syzkaller | 2016 | 操作系统内核 | 覆盖为导向的灰盒生成/变异模糊测试 | Linux | 开源 |
| TLS-Attacker | 2016 | 网络协议 | 基于语法的黑盒变异模糊测试,使用可修改变量和两阶段模糊测试 | Linux, MacOS, Windows |
开源 |
| QuickFuzz | 2016 | 应用程序 | 基于语法的黑盒生成/变异模糊测试 | Linux | 开源 |
| CAB-FUZZ | 2017 | 操作系统内核 | 灰盒模糊测试,使用混合测试 | Linux, Windows, MacOS |
未知 |
| kAFL | 2017 | 操作系统内核 | 覆盖率为导向的灰盒模糊测试, 使用虚拟机管理程序和英特尔的处理器跟踪技术 | Linux, Windows, MacOS |
开源 |
表 VI ——典型 fuzzer 及其问题领域
| 名称 | 种子生成和选择 | 输入验证和覆盖率 | 处理引发崩溃的测试用例 | 利用运行时信息 | Fuzzing 的可扩展性 |
|---|---|---|---|---|---|
| Peach | √ | √ | 〇 | × | √ |
| Trinity | / | √ | 〇 | × | √ |
| be STORM | / | √ | 〇 | × | √ |
| jsfunfuzz | / | √ | 〇 | × | √ |
| SAGE | / | √ | 〇 | √ | √ |
| Sulley | / | √ | 〇 | × | √ |
| IOCTL fuzzer | / | √ | 〇 | × | √ |
| Csmith | / | √ | × | × | √ |
| LangFuzz | / | √ | 〇 | × | 〇 |
| AFL | 〇 | × | × | √ | √ |
| YMIR | / | √ | 〇 | × | 〇 |
| vUSBf | / | √ | 〇 | × | 〇 |
| CLsmith | / | √ | 〇 | × | 〇 |
| Syzkaller | / | √ | 〇 | √ | √ |
| TLS-Attacker | / | √ | 〇 | × | √ |
| QuickFuzz | / | √ | × | × | √ |
| CAB-Fuzz | / | × | 〇 | √ | 〇 |
| kAFL | × | 〇 | × | √ | 〇 |
表中符号的意思如下所示:
种子生成和选择
√:fuzzer 可以自动生成种子或采用某种种子选择算法
〇:fuzzer 提供了一些高质量的种子供测试人员选择(通常用于基于突变的fuzzer)
×:种子由测试人员手动采集
/:fuzzer 不需要随机种子(通常用于基于语法的fuzzer)
输入验证和覆盖率
√:fuzzer 利用输入语法或其他知识生成测试用例,或采用某种方式通过输入验证
〇:fuzzer 使用了一些方法来缓解由输入验证引起的问题
×:fuzzer 不使用任何输入信息或方法来通过输入验证
处理引发崩溃的测试用例
√:fuzzer可以自动分析发现的bug,并生成详细的bug报告
〇:fuzzer 可以提供一些有用的信息,如日志文件,以帮助后续的bug分析
×:fuzzer 只生成碰撞诱导测试用例
利用运行时信息
√:fuzzer 使用运行时信息指导测试用例生成
×:fuzzer 在运行时不使用任何反馈信息
Fuzzing 的可扩展性
√:fuzzer 可以有效地测试现实世界的应用程序,并且发现了大量的bug
〇:fuzzer 正处于实验阶段,并应用于一些实际程序中
×:fuzzer 只能测试一些实验程序
A. 通用 Fuzzers(General Purpose Fuzzers)
-
Peach:Peach [112] 是一个众所周知的通用模糊器,其中最常见的目标是驱动程序、文件消费者、网络协议、嵌入式设备、系统等。它由以下组件构成:
- 预定义的输入格式定义(Peach Pits),可用作单个 Pits 或称为 Pits 包的相关 Pits 组;
- 测试通过,它可以对修改器进行加权以执行更多的测试用例
- 最小集,它有助于减少测试用例覆盖的文件数。
Peach 在该领域发挥着关键作用,因为它具有许多出色的功能,例如威胁检测、开箱即用的模糊测试定义(Peach Pits)和可扩展的测试选项。但是,Peach 中也存在一些问题(特别是在开源版本中)。一个主要的问题是使用 Peach 提供的语法来构建 Pit 文件非常耗时,以描述目标文件格式。基于 Peach,eFuzz [113] 测试了基于通信协议 DLMS/COSEM(欧洲使用的标准协议)的智能计量设备可能出现的故障。 Honggfuzz [114] 也是建立在 Peach 之上的。
-
beSTORM:beSTORM [115] 是一个商业黑盒模糊器。 它可用于测试目标应用程序的安全性或检查网络硬件和软件产品的质量。 它不需要源代码,只需要目标程序的二进制文件。 beSTORM 采取的模糊测试策略是首先测试可能的、常见的故障诱导区域,然后扩展到近乎无限的攻击变化范围; 因此,它可以快速交付结果。 beSTORM 可用于协议、应用程序、硬件、文件、WIFI 和嵌入式设备安全保证(EDSA)的测试。 例如,它能够发现实施 EDSA 402 标准的应用程序中的错误。
B. 编译器和解释器的 Fuzzers(Fuzzers for Compilers and Interpreters)
- jsfunfuzz:jsfunfuzz [116] 是一个基于语法的黑盒 fuzzer,专为 Mozilla’s SpiderMonkey JavaScript 引擎设计。它是第一个公开可用的 JavaScript 模fuzzer。 自 2007 年开发以来,它已经在 SpiderMonkey 中发现了 2000 多个 bug。 它将差异测试与目标应用的详细知识相结合; 因此,它可以有效地发现不同 JavaScript 引擎中与正确性相关的错误和触发崩溃的 bug。 但是,对于每个新的语言特性,jsfunfuzz 都必须在fuzzing 过程中进行自我调整以响应新特性。
- Csmith:Csmith 由 Yang 等人 [117] 在2011年提出。 它是一个 C 编译器模 fuzzer,可以根据 C99 标准生成具有指定语法的随机 C 程序。 它利用随机差异测试 [118] 来帮助找到由潜在未定义行为和其他 C 特定问题引起的正确性bug。 Csmith 已经使用多年,并且在商业和开源 C 编译器(例如,GNU 编译器集合 (GCC)、低级虚拟机 (LLVM))中发现了数百个以前未知的错误。 由于它是一个开源项目,关于 Csmith 的最新信息和版本可以在 [119] 中访问。 尽管 Csmith 是一个实用的模糊器,擅长生成错误诱导测试用例,但与许多其他模糊器一样,它不会根据重要性对发现的错误进行优先级排序。 因此,测试人员必须花费大量时间来决定每个 bug 的新颖性和严重性。
- LangFuzz:受 jsfunfuzz 的启发,Holler 等人 [120] 在 2012 年提出了 LangFuzz。LangFuzz 并不针对特定的语言。 到目前为止,它已经在 JavaScript 和 PHP 上进行了测试。 应用于 JavaScript 引擎后,Lang-Fuzz 在 SpiderMonkey 中发现了 500 多个以前未知的bug [26]。 应用于PHP解释器,还发现了18个可能导致崩溃的新缺陷。 LangFuzz 使用随机生成和代码变异来创建测试用例,但将变异作为主要技术。 它被设计为独立于语言的 fuzzer,但使其适应新语言需要一些必要的更改。
- CLsmith:Lidbury等人 [70] 利用随机差分测试和等效模输入(EMI)测试对多核编译器进行模糊测试,识别并报告了 50 多个 OpenCL 编译器 bug,这是商业实现中最多的。 具体来说,他们对多核设置采用了随机差分测试,以生成确定性、可通信、功能丰富的 OpenCL 内核,并提议和评估了构建死代码的注入,以在 OpenCL 环境中进行 EMI 测试。
此类别中的其他模糊器包括 MongoDB 的 JavaScriptFuzzer,它在两个发布周期中检测到近 200 个错误 [121]; Ifuzzer 是另一个使用遗传编程的 JavaScript 解释器模糊器 [122]。
C. 应用程序 Fuzzers(Fuzzers for Application Software)
- AGE:SAGE [14] 是微软开发的著名白盒 fuzzer。它用于对在 x86 平台上运行的大型文件读取 Windows 应用程序(例如,文档解析器、媒体播放器、图像处理器等)进行模糊测试。 SAGE 将 混合执行 与启发式搜索算法相结合以最大化代码覆盖率,SAGE 尽力有效地发现bug。自 2008 年以来,该工具一直在平均 100 多台机器/内核上不断运行,并自动 fuzzing 微软的数百个应用程序。 SAGE 是第一个实现白盒模糊测试技术并能够测试实际应用程序的 fuzzer 。如今,微软正在推广一个名为 Springfield 的在线模糊测试项目 [123]。它提供了包括微软白盒模糊技术在内的多种方法来查找客户上传的二进制程序中的错误。 SAGE 未来的工作包括改进其搜索方法,提高其符号执行的精度并提高其约束求解能力以发现更多错误 [38]。
- AFL:AFL [27] 是一个著名的以代码覆盖率为导向的 fuzzer。它通过代码检测收集运行时路径覆盖的信息。对于开源应用程序,检测是在编译时引入的,对于二进制文件,检测是在运行时通过修改后的 QEMU[124] 引入的。能够探索新的执行路径的测试用例在下一轮变异中更有可能被选中。实验结果表明,AFL 可以有效地发现实际用例中的 bug,例如文件压缩库、常见图像解析等。 AFL 支持 C、C++、Objective C 或可执行程序,可在类 Linux 操作系统上运行。 此外,还有一些工作来扩展 AFL 的应用场景,例如 TriforceAFL [125],使用 tofuzz 内核系统调用,WinAFL [126],将 AFL 移植到 Windows,以及来自 ORACLE 的工作 [127], 使用 AFL 模糊一些文件系统。 尽管 AFL 高效且易于使用,但仍有改进的空间。 与许多其他蛮力 fuzzer 一样,当实际输入数据被压缩、加密或与校验和捆绑时,AFL 提供有限的代码覆盖率。 此外,AFL 在处理 64 位二进制文件时需要更多时间,并且不直接支持 fuzzing 网络服务。
- QuickFuzz:QuickFuzz [128] 利用 Haskell 的 QuickCheck(著名的基于属性的随机测试库)和 Hackage(社区 Haskell 软件存储库)结合现成的位级突变模糊器为更多信息提供自动模糊测试 十几种常见的文件格式,无需提供外部输入文件集,也无需为所涉及的文件类型开发模型。 QuickFuzz 混合使用基于语法和基于变异的模糊测试技术来生成无效输入,以发现目标应用程序中的意外行为。
为了测试服务器端软件,Davis 等人 [129] 提出了Node.fz,它是一个用于事件驱动程序的调度 fuzzer,体现为服务器端Node.js 程序。 Node.fz 随机干扰 Node.js 程序的执行,允许 Node.js 开发人员探索各种可能的时间表。 该类别的工作还包括Dfuzzer [130],它是D-bus服务的 fuzzer。
为了测试移动应用程序,近年来提出了一些 fuzzer,例如Droid-FF [131],memory-leakfuzzer [132] 、DroidFuzzer [133]、intent fuzzer [134] 和 Android 应用程序的 An-droid Ripper MFT 工具 [135]。
D. 网络协议的 Fuzzers(Fuzzers for Network Protocls)
- Sulley:Sulley [136] 是一个针对网络协议的开源模糊测试框架。 它利用基于块的方法来生成单独的“请求”。 它提供了大量需要的数据格式供用户构建协议描述。 在测试之前,用户应该使用这些格式来定义所有必要的块,这些块将在模糊测试过程中进行变异和合并,以创建新的测试用例。 Sulley 可以对检测到的故障进行分类、并行工作,并追溯到触发故障的唯一测试用例序列。 然而,它目前没有得到很好的维护。 Boofuzz [137] 是 Sulley 的继任者。
- TLS-Attacker:Somorovsky [138] 提出了 TLS-Attacker,这是一个用于评估 TLS 库安全性的开源框架。 TLS-Attacker 允许安全工程师创建定制的 TLS 消息流并通过使用简单的接口来测试其库的行为来任意修改消息内容。 它成功地发现了广泛使用的 TLS 库中的多个漏洞,包括 OpenSSL、Botan 和 MatrixSSL。
还有一些其他关于模糊网络协议的工作[139],[140]。 T-Fuzz [141] 是一种基于模型的 fuzzer,用于电信协议的稳健性测试,Secfuzz [142] 用于 IKE 协议,以及 SNOOZE [143] 和 KiF [144]、[145] 用于 VOIP/SIP 协议。
E. 操作系统内核的 fuzzers(Fuzzers for OS Kernels)
操作系统中的内核组件难以 fuzz,因为反馈机制(即引导代码覆盖率)不容易应用。 此外,不确定性是由于中断、内核线程和状态带来问题[146]。 此外,如果一个进程 fuzz 了自己的内核,由于操作系统的重新启动,内核崩溃会极大地影响 fuzzer 的性能。
-
Trinity:近年来,Trinity [147] 在内核模糊测试领域获得了很多关注。 它实现了几种方法来发送系统调用半智能参数。 用于生成系统调用参数的方法描述如下:
- 如果系统调用期望某个数据类型作为参数(例如,描述符),则传递一个
- 如果系统调用只接受某些值作为参数(例如,“flags”字段),则它具有可能传递的所有有效标志的列表
- 如果系统调用只接受一个值范围,则传递给参数的随机值通常适合该范围
Trinity 支持多种架构,包括 x86-64、SPARC-64、S390x、S390、PowerPC-64、PowerPC-32、MIPS、IA-64、i386、ARM、Aarch64 和 Alpha。
-
Syzkaller:Syzkaller [15] 是另一个针对 Linux 内核的模糊器。 它依赖于指定每个系统调用的参数域的预定义模板。 与 Trinity 不同的是,它还利用代码覆盖率信息来指导模糊测试过程。 因为 Syzkaller 结合了覆盖引导和基于模板的技术,所以它比仅提供系统调用的参数使用模式更好地工作。 该工具正在积极开发中,但早期结果令人印象深刻。
-
IOCTL Fuzzer:IOCTL Fuzzer [148] 是一种旨在自动搜索 Windows 内核驱动程序漏洞的工具。 目前,它支持 Windows 7(x32 和 x64)、2008Server、2003 Server、Vista 和 XP。 如果 IOCTL 操作符合配置文件中指定的条件,则 fuzzer 将其输入字段替换为随机生成的数据。
-
Kernel-AFL (kAFL):Schumilo 等人 [149] 以独立于操作系统和硬件辅助的方式提出了覆盖引导的内核模糊测试。 他们利用管理程序产生覆盖率,利用英特尔的处理器跟踪技术提供有关运行代码的控制流信息。 他们开发了一个名为 kAFL 的框架来评估 Linux、MacOS 和 Windows 内核组件的可靠性或安全性。 在许多崩溃中,他们发现了 Linux 的 ext4 驱动程序、MacOS 的 HFS 和 APFS 文件系统以及 Windows 的 NTFS 驱动程序中的几个缺陷。
-
CAB-FUZZ:为了发现商业现成 (COTS) 操作系统 (OS) 的漏洞,Kim 等人150] 提出了 CAB-FUZZ,这是一种实用的 concolic 测试工具,用于探索最有可能触发错误的相关路径。 该 fuzzer 优先考虑数组和循环的边界状态,并利用与 COTS 操作系统交互的真实程序来构建适当的上下文,以在没有调试信息的情况下探索深层和复杂的内核状态。 它在 Windows 7 和 Windows Server 2008 中发现了 21 个未公开的独特崩溃,包括三个关键漏洞。 其中五个发现的漏洞已经存在 14 年,即使在 Windows XP 的初始版本中也可能被触发。
F. 嵌入式设备、驱动程序和组件的模糊器(Fuzzers for Embedded Devices, Drivers and Components)
- YMIR:Kim 等人 [29] 提出使用 API 级 concolic 测试自动生成模糊语法,并实现了一个工具(名为 YMIR)来自动对 ActiveX 控件进行白盒模糊测试。 它以 ActiveX 控件作为输入,并提供模糊语法作为其输出。 API 级别的 concolic 测试 在库函数级别而不是指令级别收集约束,因此可能更快且准确性较低。
- vUSBf:vUSBf [151] 首次在 Black HatEurope 2014 上提出。它是一个 USB 驱动程序的模糊测试框架。 该框架基于 KernelVirtual Machine(在 Linux 中)和 QEMU 中的 USB 重定向协议实现了一个虚拟 USB fuzzer。 它允许使用简单的 XML 配置动态定义数百万个测试用例。 每个测试都使用唯一标识进行标记,因此是可重复的。 它可以触发 Linux 内核和设备驱动程序中的以下错误:空指针取消引用、内核分页请求、内核崩溃、坏页状态和分段错误。 该领域还有一些其他工作,例如具有成本效益的 USB 测试框架[152]、VDF——虚拟设备的目标进化模糊器[153]。
除了前面提到的fuzzer,还有很多其他实用的工具,包括perf_fuzzer [154] forperf_event_open() 系统调用,libFuzzer [155] 用于库,Mod-bus/TCP Fuzzer for internetworked工业系统[156],I/O fuzzer 总线 [157]、数字证书模糊器 [158]、用于内存取证框架的 Gaslight [159] 等。此外,还有内存错误检测器(例如,Clang 的 Ad-dressSanitizer [83]、MemorySanitizer [160] 等)。 ),可以加强模糊器以暴露更多隐藏的错误而不是浅错误。
0x10 未来方向(FUTURE DIRECTIONS)
在本节中,我们通过讨论模糊测试技术的一些可能的未来方向来回答 RQ3。 虽然我们无法准确预测fuzzing研究的未来方向,但我们可以根据综述的论文识别和总结一些趋势,为未来的研究方向提供建议和指导。 我们将在以下几个方向讨论未来的工作,希望这些讨论能启发后续的研究和实践。
A. 输入验证和覆盖率(Input Validation and Coverage)
过于复杂、草率指定或错误实现的输入语言,描述了应用程序必须处理的有效输入集是许多安全漏洞的根本原因 [161]。一些系统对输入格式有严格要求(例如,网络协议、编译器和解释器等);不满足格式要求的输入将在执行的早期阶段被拒绝。为了对这种目标程序进行模糊测试,模糊器应该生成能够通过输入验证的测试用例。许多研究针对这个问题并取得了令人瞩目的进展,例如针对字符串错误的 [162]、针对整数错误的 [163]、[164]、针对电子邮件过滤器的 [165] 和针对缓冲区错误的 [166]。该领域的开放问题包括处理 FP 操作(例如,Csmith,著名的 C compilerfuzzer,不生成 FP 程序),将现有技术应用于其他语言(例如,将 CLP 应用于 C 语言)等。此外,Rawat 等人 [108] 证明通过分析应用程序行为来推断输入属性是提高模糊测试性能的可行且可扩展的策略,也是该领域未来研究的一个有希望的方向。正如我们在 0x08-A 节中提到的,虽然 TaintScope 可以准确定位校验和点并显着提高模糊测试的有效性,但仍有改进的空间。首先,它不能处理数字签名和其他安全检查方案。其次,加密的输入数据会极大地影响其有效性。第三,它忽略了控制流依赖性,不检测各种×86指令。这些仍然是悬而未决的问题。
B. 智能 Fuzzing(Smart Fuzzing)
许多其他程序分析技术被合并到智能模糊测试 [167]、[168] 中,例如 混合符号执行、动态污点分析等。虽然这些技术带来了很多好处,但它们也带来了一些问题:如路径爆炸、concolic test中不精确的符号执行以及动态污点分析中的欠污染、过度污染。例如,Dolan-Gavitte 等人 [169] 已经将数千个错误注入了八个真实世界的程序,包括 bash、tshark 和 GNUCoreutils。他们评估并发现一个突出的 fuzzer 和一个基于符号执行的错误查找器能够定位一些但不是所有注入的错误。此外,以可扩展且高效的方式进行模糊测试仍然具有挑战性。布尼莫瓦等人[107] 提出了大规模运行白盒模糊测试的关键挑战,其中涉及符号执行、约束生成和求解、长时间运行的状态空间搜索、多样性、容错和永远在线使用方面的挑战。这些问题都值得深入研究。
C. 过滤 Fuzzing 输出 (Filtering Fuzzing Outputs)
在软件开发生命周期中,修复 bug 的时间和预算通常是有限的。 因此,开发人员的主要关注点是解决那些严重的 bug。 例如,Podgurski 等人 [80] 提出了对报告的软件故障进行分类的自动化支持,以便于对它们进行优先排序并诊断其原因。 Zhang 等人 [170] 建议根据测试用例相似性度量选择测试用例来探索深层程序语义。 差异测试可能有助于确定评估测试结果的成本 [171]、[172]。 简而言之,目前很少有研究从大型模糊测试输出中过滤出更重要的导致故障的测试用例。 该研究方向具有现实意义。
D. 种子/输入 生成和选择(Seed/Input Generation and Selection)
模糊测试的结果与种子/输入文件的质量相关。因此,如何选择合适的种子文件以发现更多的 bug 是一个重要的问题。通过尝试最大化输入域的测试覆盖率,ART [58]、[173]、[174]-[176] 中处理测试用例的方法或算法可能是有用的。例如,Pacheco 等人[53]提出了一种反馈导向的随机测试生成技术,其中执行预先设计的输入并根据一组合同和过滤器进行检查。执行的结果决定了输入是多余的、非法的、违反合同的还是对生成更多输入有用。然而,在他们的大量实验中,Arcuri 和 Briand [59] 表明,在考虑测试用例之间的距离计算时,即使是在微不足道的问题上,ART 也是非常低效的。 Classfuzz [177] 使用一组预定义的变异算子对种子类文件进行变异,采用马尔可夫链蒙特卡罗采样来指导变异器选择,并使用覆盖唯一性作为接受具有代表性的准则。Shastryet 等人[178]提出通过静态分析程序控制和数据流来自动构建输入字典,并将输入字典提供给现成的模糊器以影响输入生成。设计和实现更有效、合理和准确的种子生成和选择算法是一个开放研究问题。
E. 结合不同的测试方法(Combining Different Testing Methods)
正如 0x07 所讨论的,黑盒和白盒/灰盒模糊测试方法各有优缺点。因此,如何结合这些技术来构建既有效又高效的 fuzzer 是一个有趣的研究方向。在这方面有一些尝试 [124]、[179]、[48],例如,SYMFUZZ [51] 使用白盒技术增强了基于黑盒突变的模糊测试,这有助于计算基于在给定的程序种子对上。从微观角度来看,SYMFUZZ 生成测试用例有两个主要步骤,每个步骤使用不同的模糊测试技术,即白盒模糊测试和黑盒模糊测试。但是,从宏观上看,这种方法也可以看作是灰盒模糊测试。由于其黑盒 fuzzing 过程的变异率是在其白盒 fuzzing 过程中计算的,所以整个 fuzzing 利用了目标程序的部分知识,可视为灰盒 fuzzing。 将模糊测试与其他测试技术相结合也是一个有趣的方向。 Chen 等人 [180] 报道了编制测试 [181]-[183] 是一种相对较新的测试方法,它着眼于多个程序执行的输入和输出之间的关系,检测现实世界关键应用程序中以前未知的错误,表明使用不同的视角并结合 多种方法可以帮助软件测试实现更高的可靠性或安全性。 Garnand Simos [184] 展示了一种利用组合测试和模糊测试的综合方法对 Linux 内核的系统调用接口的适用性。
F. 将其他技术与 fuzzing 技术相结合
Fuzzer 受限于测试覆盖范围和合适测试用例的可用性。由于静态分析可以对易受攻击的代码模式进行更广泛的搜索,从少数模糊器发现的程序故障开始,Shastry 等人 [185] 实现了一种简单而有效的匹配排序算法,该算法使用测试覆盖数据将注意力集中在包含未经测试代码的匹配上,并证明静态分析可以有效地补充模糊测试。 静态分析技术,例如符号执行和 控制/数据流分析,可以为模糊测试提供有用的结构信息[186];然而,模糊测试的符号执行存在一些限制,因此留下了一些未解决的问题: 1) 仅检查通用属性——未发现与指定行为的许多偏差 2) 许多程序并不完全适合符号执行,因为它们会产生硬约束,因此程序的某些部分仍未被发现[187]
Havrikov [188] 提出了一种组合方法,模糊测试可以从不同的轻量级分析中受益。分析利用了目标程序之外的多个信息源,例如输入和执行(例如,以扩展上下文无关语法形式描述的目标输入格式)或硬件计数器。
机器学习技术有助于自动生成基于语法的模糊测试的输入语法 [189]。优化理论也可用于在模糊测试中构建有效的搜索策略 [83]、[190]、[191]。 [122]、[192] 和 [193] 中使用遗传编程或算法来指导他们的 fuzzer。 Dai 等人 [194] 提出了一种新颖的 UI 模糊测试技术,旨在运行应用程序,以便可以执行不同的执行路径,并且该方法需要测试人员构建全面的网络配置文件。 我们认为在改进现有组合方法和利用其他技术进行模糊测试方面仍有一定的空间。
0x10 参考文献
194篇就不列了,详见原文:https://ieeexplore.ieee.org/document/8371326/references#references